Use Cases
Docs
Blog
About Us
Pricing
Sign up
Tracto service is going to be discontinued on Feb 28th
Please back up all important data; if you have any questions, reach us by
support@tracto.ai
Train your own AI models
Use Tracto to train your own AI models
Start building
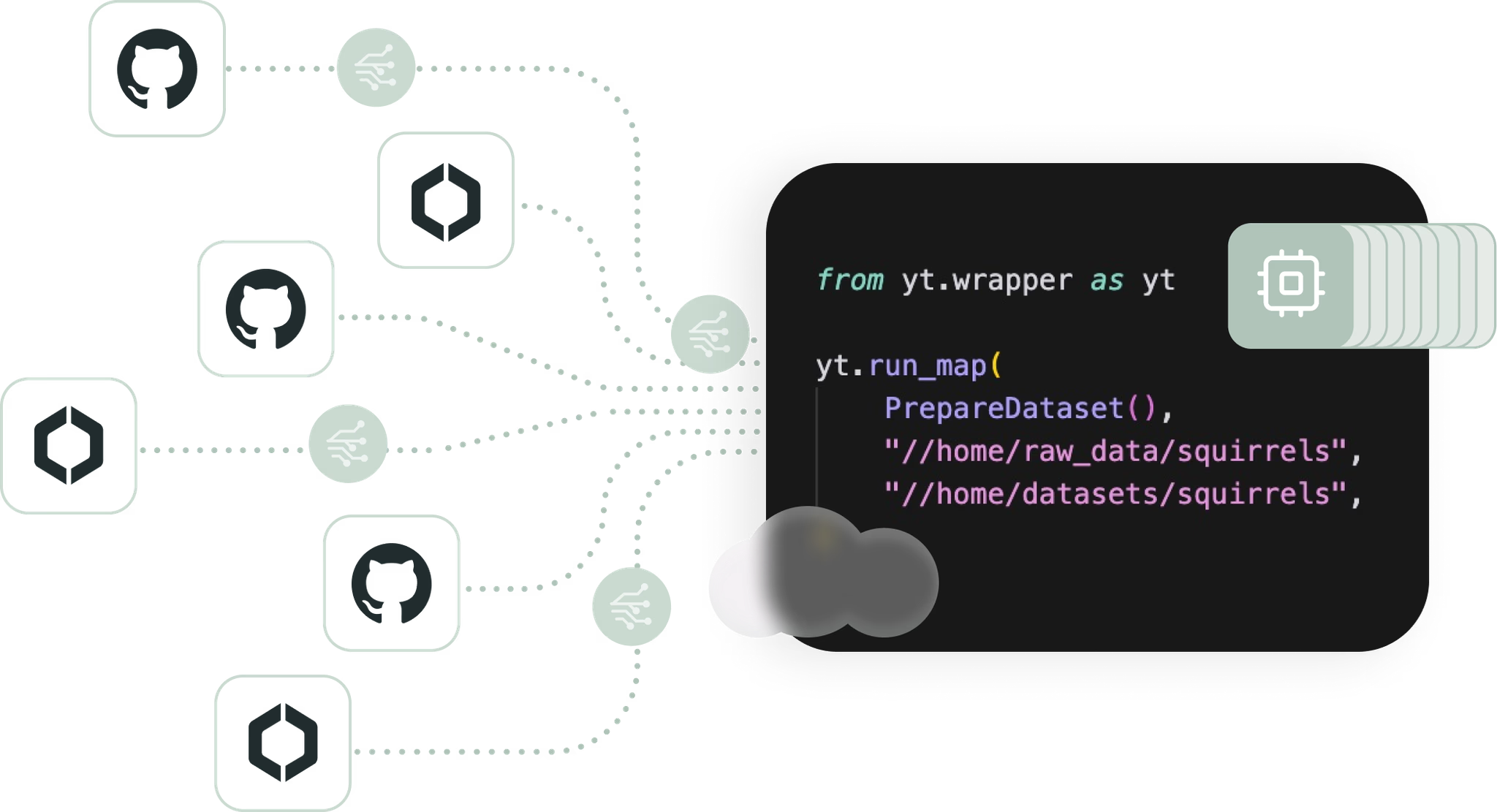
Prepare a training dataset
Leverage pre-built functions to pull and process public data from CommonCrawl, Github or S3 storage
Store all datasets (raw, in-progress, final) in Tracto Cypress prior to model training
Leverage serverless GPUs and CPUs to run data preparation tasks at scale
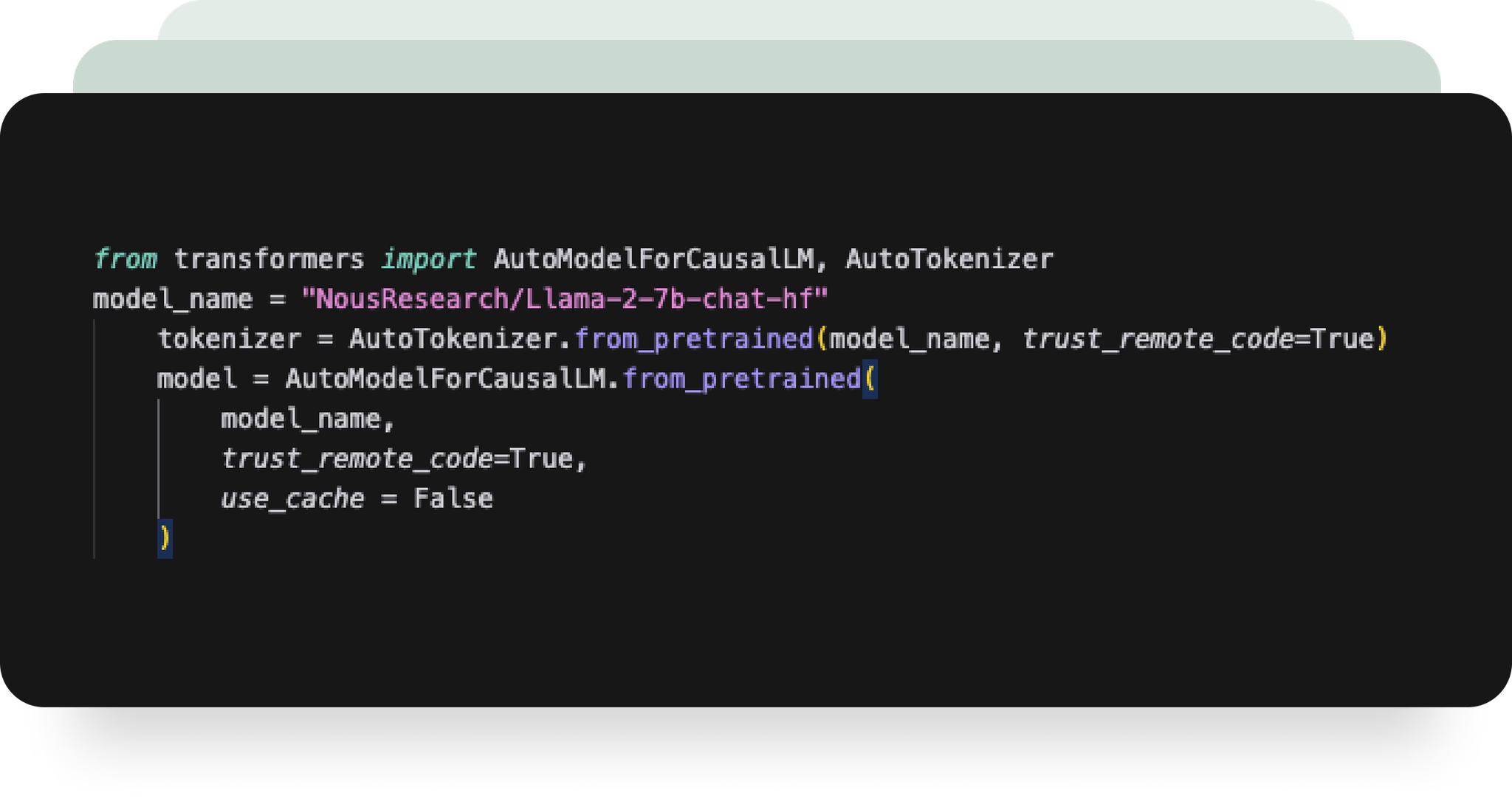
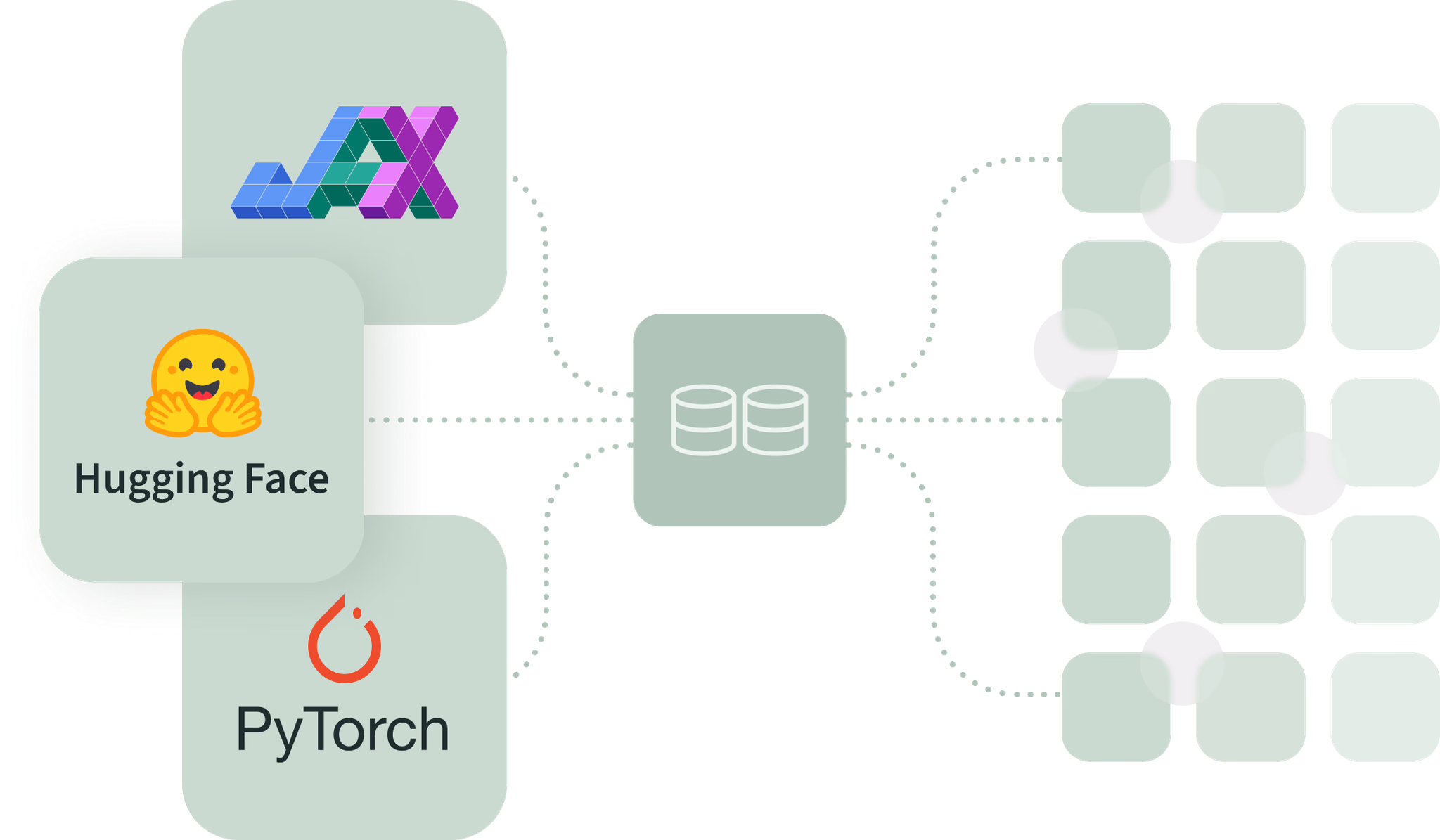
Train your model
Use your favorite fine-tuning frameworks, like PyTorch, Jax, Hugging Face
Store checkpoints in Tracto Cypress
Scale training jobs to hunderds of GPUs
Monitor results on W&B
Post training
Improve pretrained model to handle specific tasks.
Evaluate trained model via offline inference
Deploy your model
Infer your model at scale.
Download model weights.
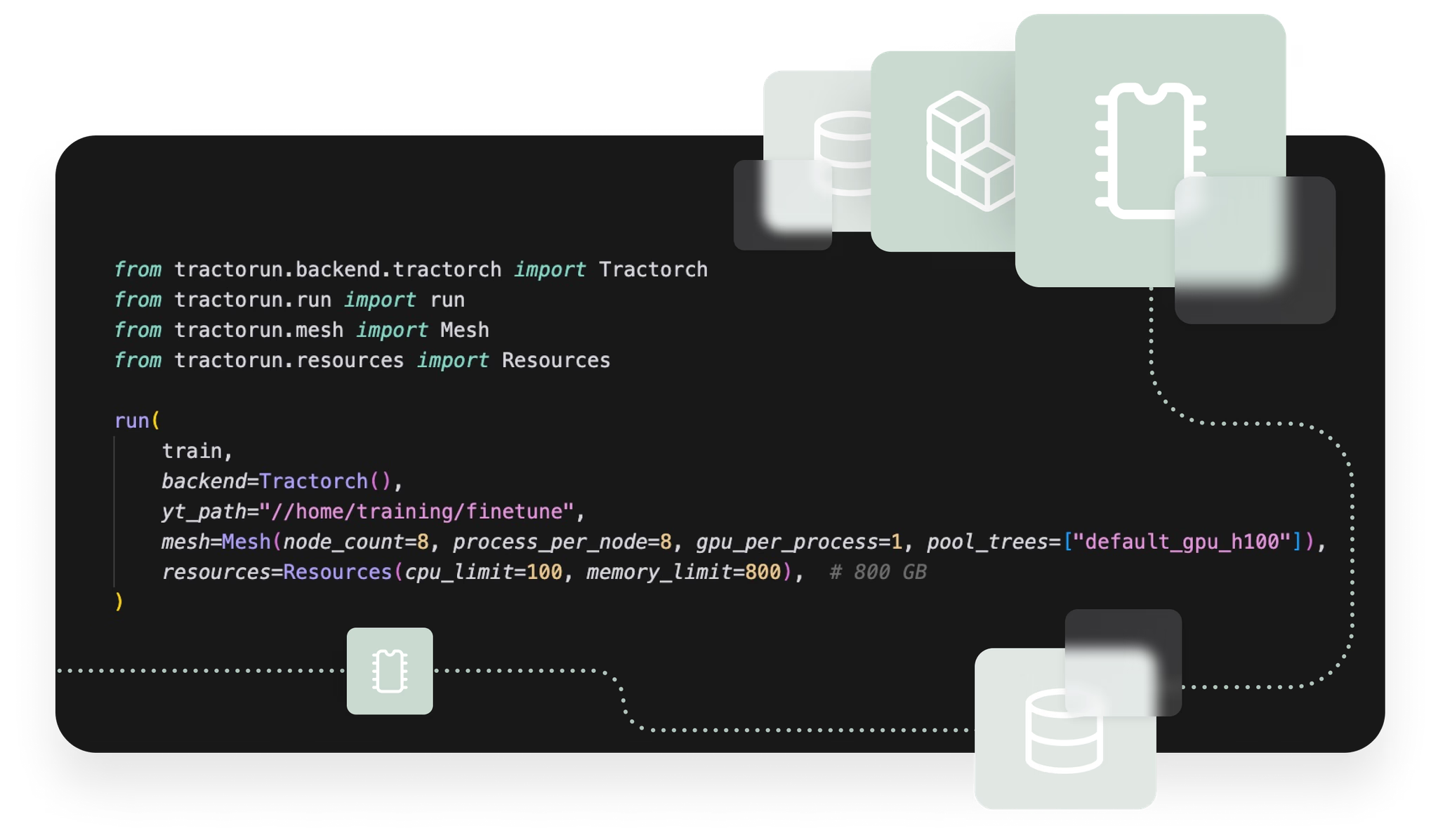
Infrastructure
Access GPU infra from Python code
Choose from pre-built Docker images or bring your own image
Run multi GPU training jobs with a few lines of code
Try it on TractoAI
Train an image classifier with PyTorch
Train an image classifier with Pytorch using distributed multi-node GPU acceleration
Teams choosing to build with TractoAI